
RAG vs. Context Windows: It's not OR but AND
The Context Window Explosion—and Why RAG Still Matters

When ChatGPT first launched in late 2022, its context window was capped at 4,000 tokens—roughly 3,000 words. Push it much beyond that, and the model would lose track, wander off-topic, or hallucinate.
Fast forward to today:
128k tokens (about a 250-page book) is becoming the new standard.
Frontier models now stretch up to 1M tokens, with research systems claiming 10M–100M tokens in context.
That’s an incredible leap. But does it mean we can throw away retrieval-augmented generation (RAG)? Not quite.
Large context window models today
Here’s a snapshot of where leading models stand, arranged from the largest to the smallest context windows:
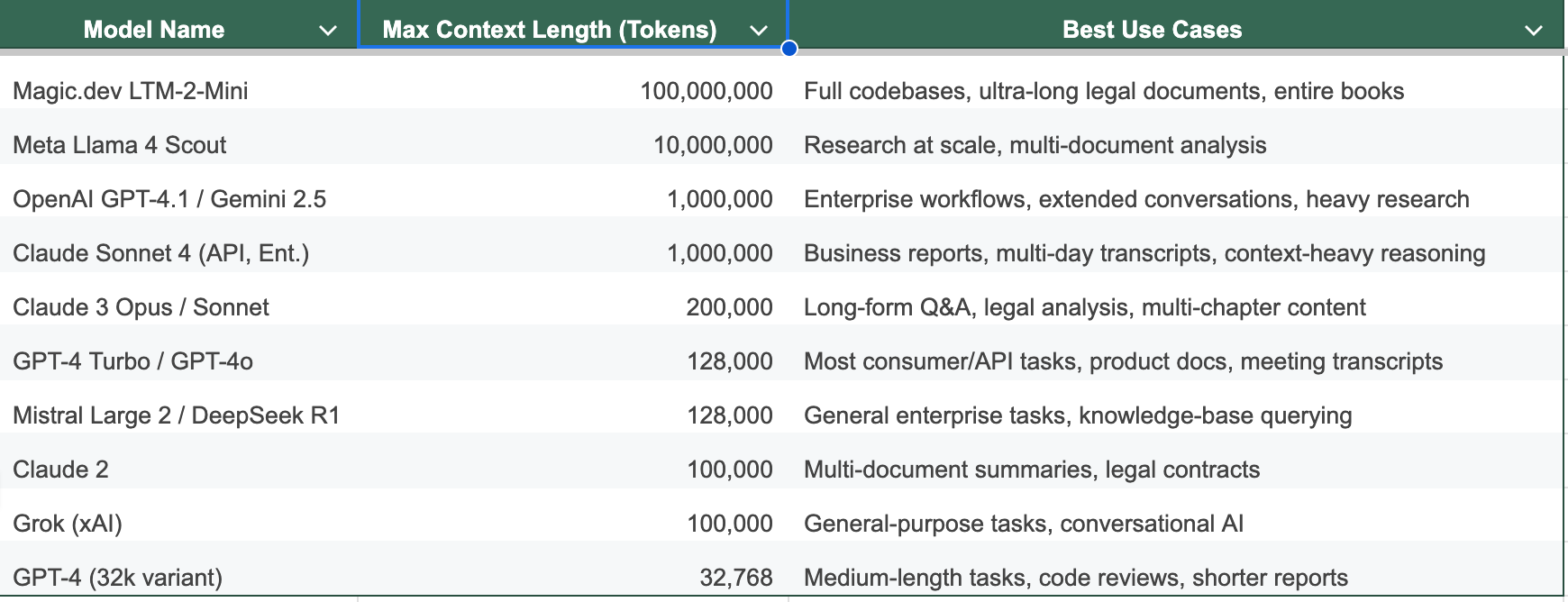
Quick tiers summary
Ultra-Long Tier (10M–100M tokens): Magic.dev, Meta Llama 4 Scout → for codebases, books, or research-scale input.
Enterprise / Million-Token Tier: GPT-4.1, Gemini 2.5, Claude Sonnet 4 → for research, enterprise workflows, long transcripts.
Mid-Tier (~128k–200k tokens): GPT-4 Turbo, GPT-4o, Mistral, Claude 3 Opus → good balance of cost and performance for most use cases.
Compact Tier (32k–100k tokens): Claude 2, Grok, GPT-4 (32k) → efficient for shorter docs, everyday tasks.
👉 Rule of thumb: Go ultra-long only if you really need it. For 90% of workflows, the 128k tier is more than enough, balancing cost, latency, and performance.
(Remember: each token is ~4 characters, so 128k tokens = hundreds of pages in one prompt.)
The limits of “just make it bigger”
Bigger context windows sound like a silver bullet—but they come with real trade-offs:
Cost & latency – Passing 100k+ tokens costs more and slows inference.
Overload risk – LLMs, like humans, miss buried details in long text. They’re most sensitive to the start and end of a prompt.
Quadratic scaling – Doubling input length means ~4x the compute and memory required.
So while longer context windows open new doors, they don’t make RAG irrelevant.
RAG: Still essential
Retrieval-Augmented Generation (RAG) was built for an earlier era of smaller context windows. Instead of shoving everything into the prompt, it smartly selects the most relevant snippets from a knowledge base and passes them in.
Now that windows are larger, some ask: do we still need RAG? The answer: yes—absolutely. If anything, RAG is even more important when context gets bigger, because it ensures the model isn’t drowning in irrelevant details.
Here’s how they compare:
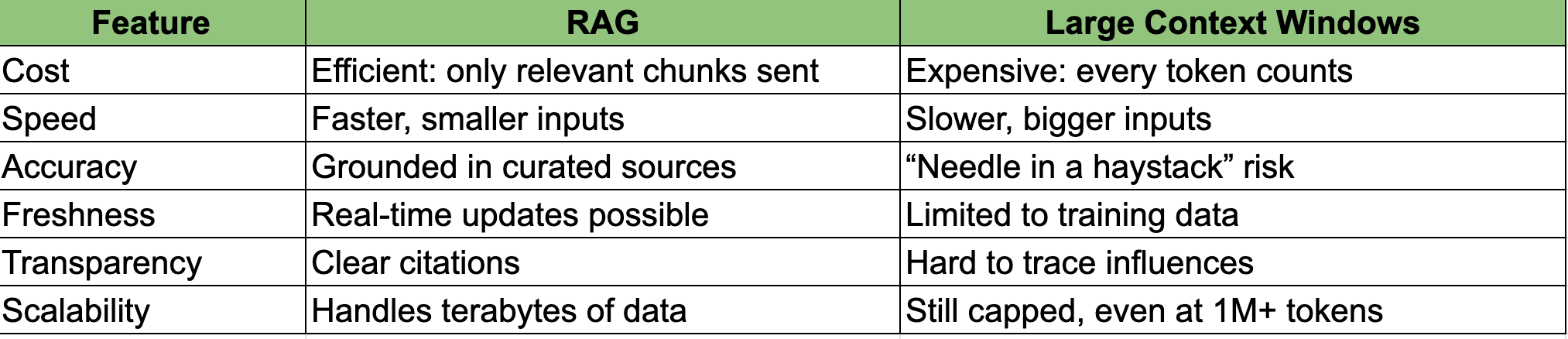
When to use what
✅ Use large context windows for:
Analyzing a single very long document (e.g., a legal contract, a book, or a full transcript).
Predictable, repetitive tasks with a small static knowledge base.
✅ Use RAG for:
Real-time or frequently updated data.
Enterprise-scale datasets (where fitting everything into context is impractical).
Accuracy-critical fields needing citations (law, healthcare, compliance).
The hybrid future
The real power comes when the two approaches work together:
RAG retrieves the freshest and most relevant information.
The large context window gives the model room to reason across it, plus longer conversation history.
Think of it as combining a great research assistant (RAG) with a model that has a massive working memory (context windows).
Final thought
Context windows have grown from a cramped closet into a vast auditorium. But more space doesn’t automatically mean better answers. The challenge is using that space wisely.
RAG isn’t going away—in fact, in the era of million-token models, it may become even more important as the curator that ensures what goes into that space really matters.
The future isn’t RAG vs. context windows.
It’s RAG + context windows, working together.